
About Us
We apply statistics, mathematical modeling, machine learning and artificial intelligence to uncover deep insights from high throughput biological datasets. Next we interpret complex biological relations with deep expertise in immunology and molecular biology.
We bring in 15 years of data science experience from big pharma and biotech companies. Our leadership team has successfully led multiple clinical, translational and discovery projects in oncology, infectious disease, cardiovascular and auto-immune diseases.
Our Approach from Data to Decision
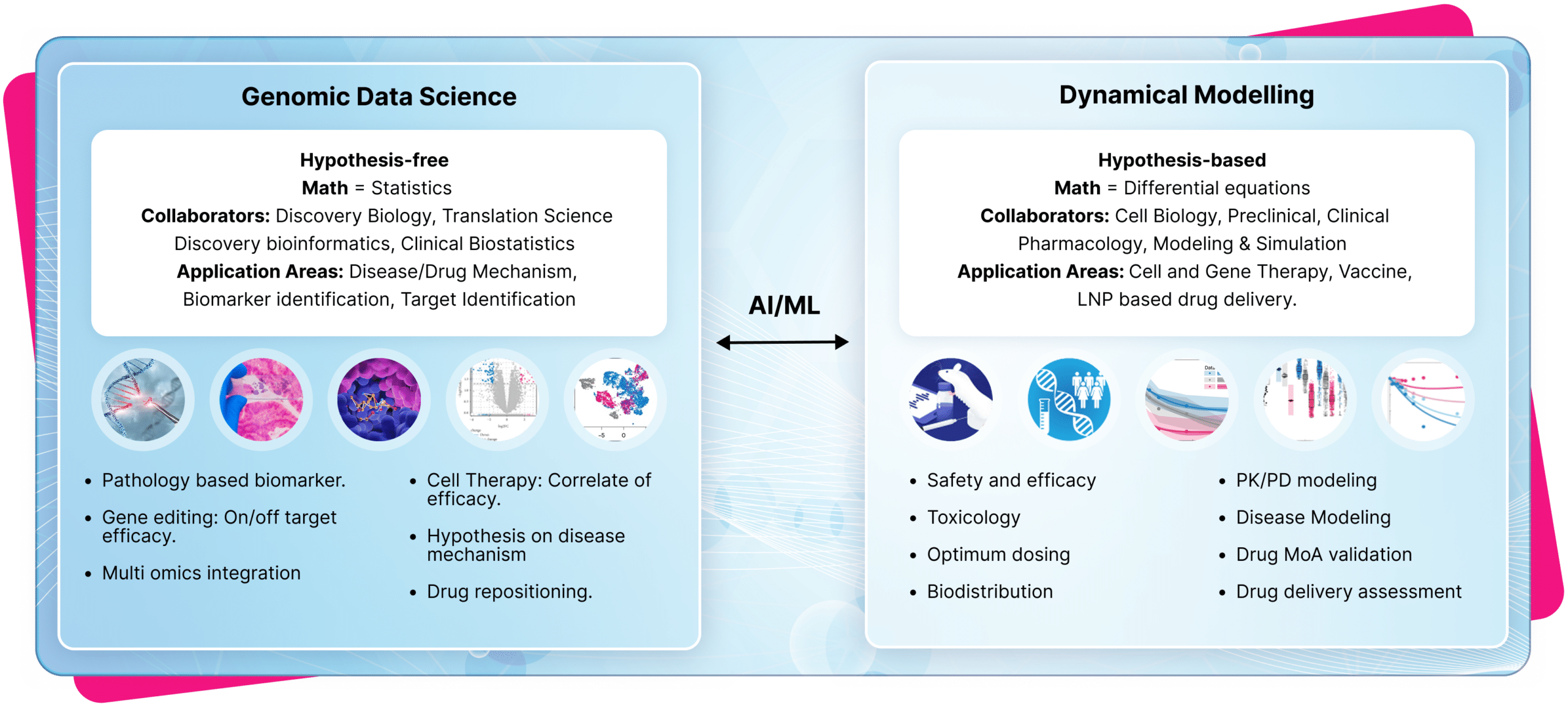
In the pharmaceutical and biotech sectors, Genomic Data Science and Dynamical Modelling serve as foundational pillars for data-driven decision making. Yet, these disciplines often function in isolation. We transformed this paradigm by cultivating collaboration—bringing together experts from both domains to exchange ideas and co-create innovative solutions.
Career openings
Introduction to Role:
At Symba Genomics, we work at the intersection of big data analytics and biological interpretation providing scientists with a one-stop solution for all Omics analysis and interpretation. Our leadership team has successfully led multiple clinical, translational and discovery projects in oncology, infectious disease, cardiovascular and auto-immune diseases.
Join Symba Genomics as Bioinformatics Scientist in our Genomics Data Science division, India. This is a great opportunity to collaborate with scientists from our global clientele across multiple locations. You will be applying cutting edge data science to analyse high throughput genomic data, enable new computational capabilities. The position will offer opportunity to collaborate with industry leaders, and contribute directly to the development of genomic medicine or sustainable genomic products.
Responsibilities:
As a Bioinformatics Scientist, you will build computational capabilities to advance multi-omics data analysis and interpretation including genomics, epigenomics, transcriptomics and proteomics, at both the bulk and single cell resolution. You will develop hypothesis generation by developing novel data science workflows and integrate multi-omics data and combining biological insights. You will also implement new predictive modeling to understand disease mechanism or drug mode of action.
Essential Skills/Experience:
- PhD in computational or decision science (e.g., computational biology, bioinformatics, genomics or computer science) is preferred; or MSc (or equivalent) with experience in independent research in high-throughput omics data will also be considered
- Extensive experience in multiple large-scale omics data types, including transcriptomics, proteomics, metabolomics, epigenetics, genomics or CRISPR gene editing data analysis.
- Experience developing predictive modeling for patient stratification.
- Expertise in data science techniques, such as AI, machine learning and classical/Bayesian statistics.
- Strong programming skills in R or Python, together with data visualisation frameworks
- Team player mindset and ability to explain complex topics to scientists from other disciplines
- Demonstrated evidence of leading highly collaborative cross-functional teams
- Prior experience in the bio pharmaceutical industry and general understanding of drug development and pharmacology
Please email your resume and cover letter at info@symbagenomics.com
Deatils of members
Accordion Content